Systém řízení budovy založený na analýze obrazu využívající umělou inteligenci
Výzva: 35. Veřejná grantová soutěž, OPEN-35-15
Hlavní řešitel: Artem Moroz
Instituce: České vysoké učení technické v Brně
Oblast: informatika
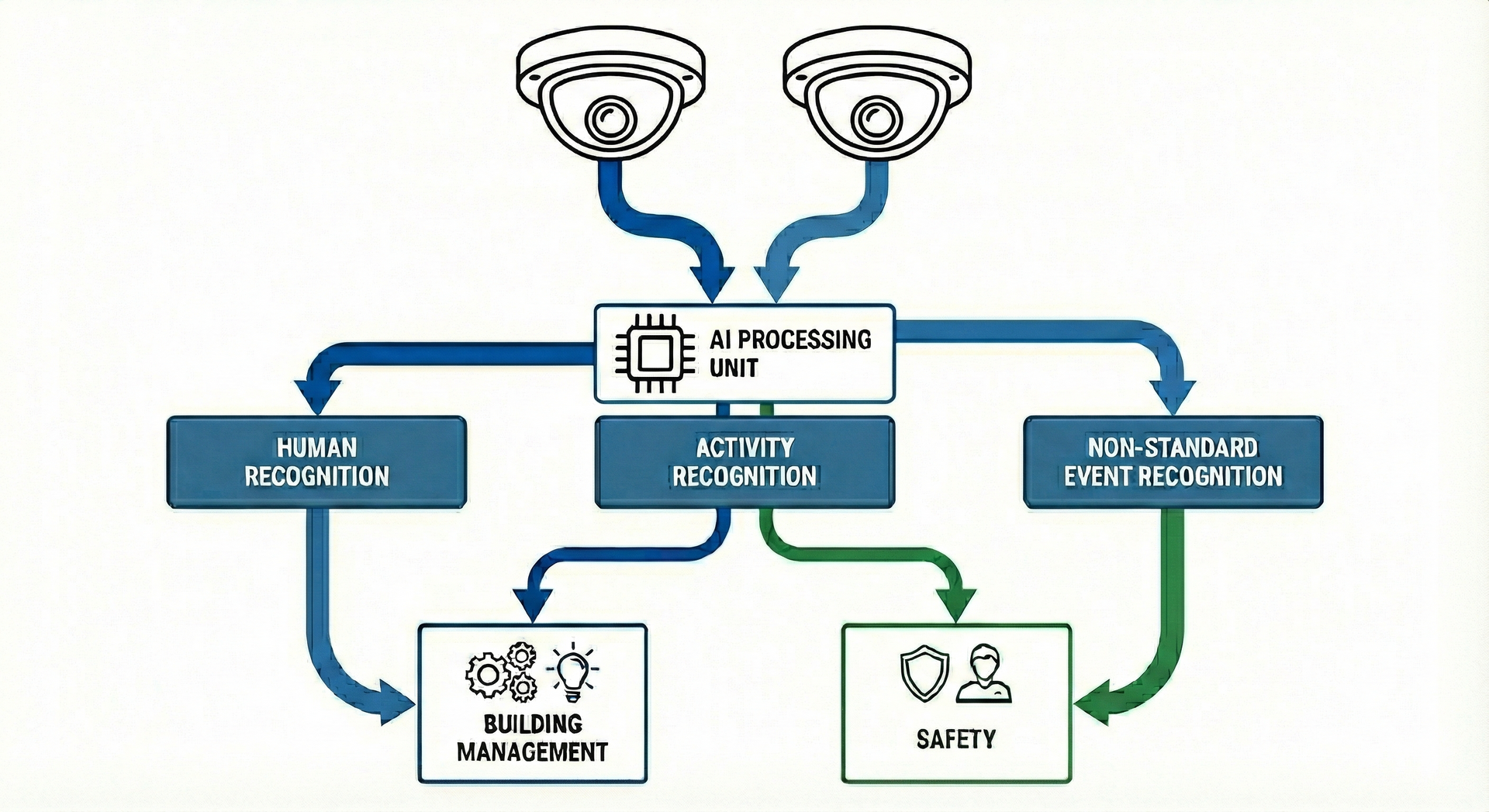
Artem Moroz z Českého vysokého učení technického v Praze využije superpočítač Karolina k vývoji inteligentního systému správy budov založeného na analýze obrazu. Systém bude pomocí umělé inteligence a kamer umístěných na stropě schopen detekovat lidi, identifikovat jejich činnosti a v reálném čase rozpoznávat kritické situace, čímž umožní automatickou reakci. Vývoj takové technologie přinese bezpečnější veřejné prostory, podporu péče o seniory a pacienty a efektivnější řízení spotřeby energie v tzv. chytrých budovách.
Tento výzkum je součástí stejnojmenného projektu (FW11020202), podpořeného Technologickou agenturou ČR.
Vyhledávání obrázků podle podrobného popisu objektů
Výzva: 35. Veřejná grantová soutěž, OPEN-35-7
Hlavní řešitel: Vladan Stojnić
Instituce: České vysoké učení technické v Praze
Oblast: informatika

Představte si, že se snažíte najít fotografii své dětské plyšové opičky v obrovské sbírce obrázků. Nejen jakékoli plyšové opičky, ale té vaší, která vypadá jako orangutan, má chlupatou červenohnědou srst, velké kulaté oči, světle béžovou tvář, suchý zip na rukou a vyšitý úsměv. Většina dnešních nástrojů pro vyhledávání obrázků by jednoduše vrátila obecné obrázky plyšových opiček. Často jim unikají konkrétní detaily, na kterých záleží nejvíce. Cílem Vladana Stojniće z Českého vysokého učení technického v Praze je s pomocí superpočítače LUMI vyvinout metodu, která dokáže najít obrázky na základě podrobných popisů na úrovni objektů. Aby toho tým z ČVUT dosáhl, plánuje vycházet z nejnovějších modelů, které propojují obrázky a text, a trénovat je pomocí dat navržených právě pro tento úkol. Upraví také způsob, jakým se tyto modely učí, aby lépe rozuměly jemným detailům, které odlišují jeden objekt od druhého.
AI pro bezpečnou dopravu a energeticky efektivní budovy
Výzva: 35. Veřejná grantová soutěž, OPEN-35-29
Hlavní řešitel: Petr Strakoš
Instituce: IT4Innovations
Oblast: informatika

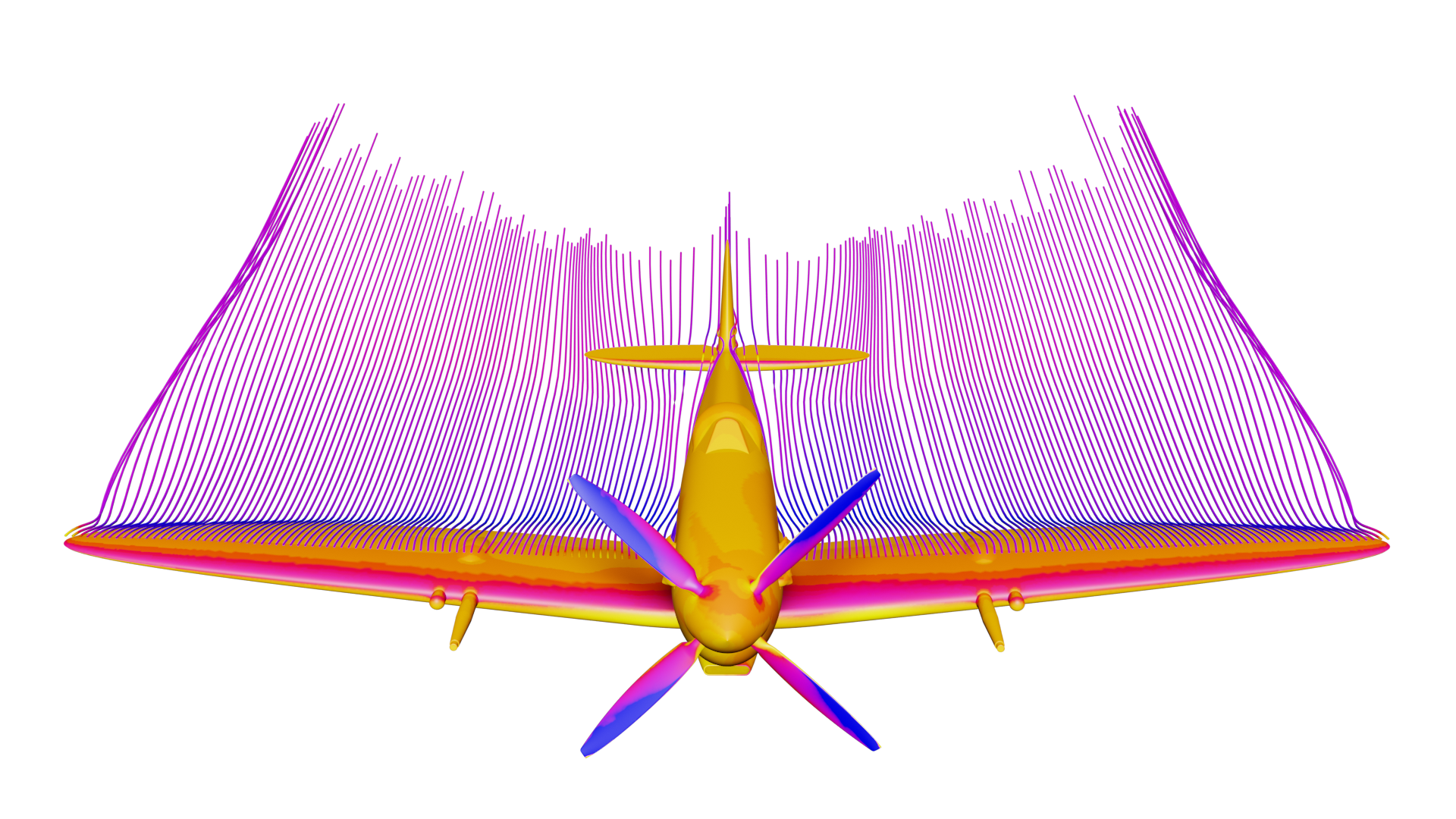
Obrázek ukazuje synteticky vygenerovaná obrazová data z virtuálního 3D prostředí určená pro vývoj AI algoritmů v oblasti dopravy.
Tým z IT4Innovations využije superpočítače Karolina, LUMI a Barbora NG pro vývoj inteligentních systémů pro bezpečnou dopravu a efektivní řízení energií ve městech a chytrých budovách. Zaměří se na rozpoznávání objektů, detekci lidských aktivit a odhalování anomálií v reálném čase pomocí umělé inteligence. Pro trénink algoritmů využijí mimo jiné synteticky generované vizuální scénáře z 3D prostředí, které umožní simulovat složité nebo vzácné situace, jež nelze snadno zachytit ve skutečném světě. Výsledkem budou systémy nové generace, schopné rychle a spolehlivě reagovat v kritických situacích. Tento výzkum je realizován v rámci mezinárodní spolupráce a projektu InnovAIte.
Pokročilé rozpoznávání mluvčích pomocí umělé inteligence
Výzva: 33. Veřejná grantová soutěž; OPEN-33-6
Hlavní řešitel: Lukáš Burget
Instituce: Vysoké učení technické v Brně
Oblast: informatika

Lukáš Burget z Vysokého učení technického v Brně využije superpočítače Karolina a LUMI k vývoji pokročilého systému rozpoznávání řeči. Cílem je vytvořit technologii, která si poradí s více mluvčími hovořícími současně, a to i v hlučných a akusticky náročných prostředích za použití vícero mikrofonních vstupů. Tým naváže na úspěšné využití velkých předtrénovaných modelů, jako je OpenAI Whisper, a zaměří se na jejich úpravu a propojení s doplňkovými nástroji, například pro diarizaci mluvčích nebo separaci zvukových zdrojů. Výsledkem bude robustní systém, který najde uplatnění nejen ve výzkumu, ale i v praxi – například ve zdravotnictví, chytré domácnosti či krizové komunikaci.
Výzkum je podpořen z evropských programů Horizon Europe (projekt ELOQUENCE) a Marie Skłodowska-Curie (projekt ESPERANTO), stejně jako z národních projektů Ministerstva vnitra ČR (projekty „112“ a NABOSO), které se zaměřují mimo jiné na bezpečnost, důvěryhodnost AI a boj proti hlasovým deepfakům.
Univerzální metoda pro úlohy porozumění videu
s jazykovým ukotvením
Výzva: 33. Veřejná grantová soutěž, OPEN-33-23
Hlavní řešitel: Evangelos Kazakos
Instituce: Český institut informatiky, robotiky a kybernetiky,
ČVUT v Praze
Oblast: informatika

Výstup modelu GROunded Video caption gEneration (GROVE) na instruktážním videu. Model generuje titulky na úrovni videa (dole) s klíčovými podstatnými jmény v popiscích videa, které jsou barevně označeny a lokalizovány (ukotveny) ve videu pomocí časově konzistentních ohraničujících rámečků (nahoře).
Evangelos Kazakos z týmu Inteligentní strojové vnímání při Českém institutu informatiky, robotiky a kybernetiky (CIIRC) Českého vysokého učení technického v Praze využívá superpočítač LUMI k vývoji univerzálního modelu neuronové sítě pro zpracování videa a přirozeného jazyka. Tento model je navržen tak, aby zvládal širokou škálu úloh prostorově-časového ukotvení v dlouhých videích. Integruje velký jazykový model (LLM) pro interpretaci požadavků úloh a generování popisů videí, spolu s modulem vizuálního ukotvení, který identifikuje jak časový rozsah popisovaných aktivit, tak ohraničující rámečky relevantních objektů.
Stávající modely čelí zásadním výzvám v oblasti prostorově-časového uvažování – zejména u dlouhých videí – což je schopnost klíčová pro aplikace jako je robotická manipulace nebo autonomní řízení. Cílem tohoto projektu je sjednotit různé úlohy ukotvení ve videu do jednoho flexibilního rámce a nabídnout tak komplexnější řešení. Výsledky by mohly umožnit robotům vykonávat manipulaci s objekty na základě přirozeného jazyka a zlepšit komunikaci mezi autonomními vozidly a lidskými řidiči, čímž by přispěly k bezpečnější a intuitivnější interakci.
Tento výzkum je součástí projektu ERC Advanced Grant FRONTIER (GA č. 101097822).
Trénování rozsáhlého dynamického modelu robotické manipulace objektem z videa
Výzva: 32. Veřejná grantová soutěž, OPEN-32-10
Hlavní řešitel: Georgij Ponimatkin
Instituce: České vysoké učení technické v Praze
Oblast: informatika

Výzkumníci z Českého institutu informatiky, robotiky a kybernetiky (CIIRC ČVUT) využijí přidělený výpočetní čas na superpočítači LUMI k vývoji rozsáhlého dynamického modelu, který dokáže předpovídat trajektorie pohybu ve 2D prostoru na základě textu popisujícího požadované akce. Například při zadání fotografie osoby držící láhev s vodou a popisku typu „nalij vodu do hrnku“ bude model předpovídat dráhu pohybu této akce. Těmito predikcemi pak lze řídit robotické systémy při provádění úkolů, což představuje další posun v oblasti robotické manipulace. Tento výzkum je financován z grantu ERC Advanced Grant „FRONTIER“ grantové č. 101097822.
Základní český jazykový model
Výzva: 31. Veřejná grantová soutěž; OPEN-31-52
Hlavní řešitel: Petr Marek
Instituce: České vysoké učení technické v Praze
Oblast: informatika

Petr Marek z Českého vysokého učení technického v Praze (ČVUT) plánuje využít výpočetní sílu superpočítačů Karolina a LUMI k vývoji moderního jazykového modelu pro češtinu, který bude schopen porozumět, generovat a interagovat s textem.
Tento projekt se zaměří na vytvoření základního českého jazykového modelu s důrazem na maximální efektivitu, škálovatelnost a výkon, využívající nejmodernější výpočetní techniky a platformy jako CUDA, open-source knihovnu Transformers od Hugging Face a Hugging Face Accelerate.
Cílem je také případně vytvořit dvojjazyčnou česko-anglickou verzi modelu, která by mohla být rozšířena o další středoevropské jazyky, inspirovaná pokročilými jazykovými modely Phi. Výzkumníci z ČVUT plánují použít rozsáhlý dataset obsahující 350 miliard českých tokenů.
Zjišťování ekonomických názorů a příčinných souvislostí z textových dat
Výzva: 30. Veřejná grantová soutěž; OPEN-30-3
Hlavní řešitelka: Jennifer Za Nzambi
Instituce: České vysoké učení technické v Praze
Oblast: informatika

Sociální sítě jsou cosi jako dosud nevyužitá zlatonosná žíla, která skrývá rezervoár názorů, postojů a nálad veřejnosti, a pokud by byly využity, mohly by způsobit převrat ve způsobu, jakým se shromažďují a interpretují názory veřejnosti.
V tomto projektu je představena nová metoda získávání názorů na ekonomické ukazatele a faktory ovlivňující společnost z příspěvků na sociálních sítích pomocí vyladění rozsáhlých jazykových modelů na souborech dat obsahujících příspěvky na sociálních sítích, komentáře a další. Díky vyladění mohou jazykové modely získat schopnost porozumět ekonomickému vyjadřování v příspěvcích zveřejněných na sociálních sítích a napodobit je. Hodnota tohoto projektu je trojí. Předně spojuje pečlivě sestavené datové soubory, díky nimž se model může efektivně učit doménovým specifikům a ekonomickému porozumění na pokročilé úrovni. Dále vytváří metriky založené na porovnávání perplexity protichůdných výroků, které ověřují porozumění ekonomických textů modelem, čímž měří soulad modelu s datovými sadami, na nichž byl vyladěn, a nakonec aplikuje zmíněné modely na datové sady, přičemž získává výsledky naznačující, že přístup založený na modelu může soupeřit a v některých případech překonat předpovědi založené na průzkumech a odborné prognózy trendů ekonomických ukazatelů.
Nad rámec této studie by předložené metody a zjištění mohly připravit půdu pro další aplikace vylaďování jazykových modelů jako doplňku nebo potenciální alternativy k tradičním metodám založeným na průzkumech.
Tento výzkum je financován Evropskou radou pro výzkum (ERC) v rámci programu Evropské unie pro výzkum a inovace Horizont 2020 (grantová dohoda č. 101002898).3D rekonstrukce a porovnání metod pro hledání korespondencí mezi obrazy (feature matching)
Výzva: 30. Veřejná grantová soutěž; OPEN-30-13
Hlavní řešitelka: Assia Benbihi
Instituce: České vysoké učení technické v Praze
Oblast: aplikovaná matematika
3D rekonstrukce neboli 3D mapování je úloha počítačového vidění, která vytváří digitální 3D modely scény. 3D modely mohou mít různou podobu, nejčastěji se jedná o 3D mračna bodů a sítě. Umožňují inteligentním systémům vnímat fyzický prostor, což je předpokladem pro to, aby se systém lokalizoval v prostředí, pochopil, co ho obklopuje, a následně zvolil vhodný postup. 3D mapování je klíčovou technologií pro mnoho aplikací, včetně autonomní navigace, aplikací virtuální a rozšířené reality, tvorby 3D obsahu pro filmy a hry, plánování měst a životního prostředí a dokumentace kulturního dědictví
Při mapování se nejprve scéna naskenuje různými senzory (kamerami nebo laserovými skenery) a následně se získaná data integrují v rámci optimalizačního procesu tak, aby vznikla 3D mapa, která věrně kopíruje reálný svět. Přirozeně zde vyvstává otázka: jak změřit věrnost 3D mapy. Jinými slovy, jak změřit kvalitu mapování?
Evaluační benchmarky odpovídají na tuto otázku tím, že využívají přesné 3D modely scén, které fungují jako „pseudo ground truth“ digitální dvojčata. Jakoukoli metodu 3D mapování pak lze hodnotit podle toho, jak věrně odpovídá tomuto digitálnímu dvojčeti. Takové hodnocení je spolehlivým měřítkem, ale generování pseudo ground truth map klade příliš velké nároky na výpočty, což ztěžuje tvorbu 3D mapovacích benchmarků.
V tomto projektu je navržen nový 3D mapovací benchmark zaměřený na rozsáhlé městské scény, které zahrnují známé pražské památky, jako je Staroměstské náměstí nebo Pražský hrad. Přístup k superpočítačům usnadňuje tento výpočetně náročný projekt, jehož složitost spočívá v intenzivní optimalizaci, která generuje pseudo ground truth mapy, ve vyhodnocení nejmodernějších metod, které jsou založeny na pokročilých grafických kartách, a ve velikosti benchmarku.
Část zveřejněných dat, především geolokační snímky, jsou výsledkem předchozího projektu Karolina OPEN-28-60 "The Prague Visual Localisation Benchmark" a výsledný benchmark bude nástrojem pro výzkum v oblasti 3D mapování.
Tento projekt je součástí projektu GAČR EXPRO s názvem " Sjednocená reprezentace 3D map" (23-07973X), jímž je také financován a jehož jedním z výstupů je metoda 3D mapování 'Tetra-NeRF', která je prezentována na videu a která vznikla za přispění projektu Karolina OPEN-24-6.
Výzva: 30. Veřejná grantová soutěž; OPEN-30-22
Hlavní řešitelka: Mireia Diez Sánchez
Instituce: Vysoké učení technické v Brně
Oblast: informatika
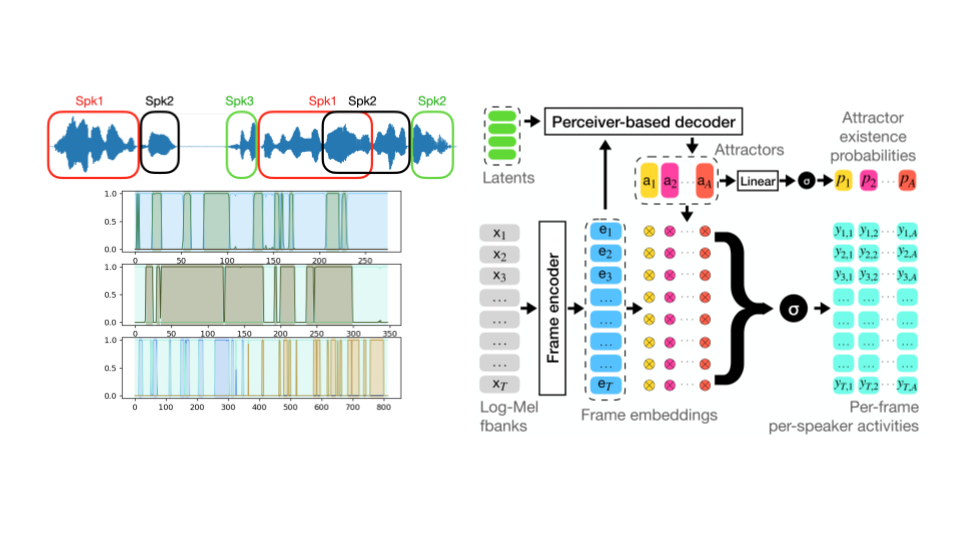
Diarizace mluvčího (Speaker diarization, SD) je úloha automatického určování střídání mluvčích v audiozáznamu obecně známá jako úloha, která přináší odpověď na otázku "kdo kdy mluvil"?. SD má několik praktických aplikací: mimo jiné indexování audiovizuálních záznamů s označením mluvčího (například obarvení titulků v závislosti na mluvčím), umožnění strukturovaného vyhledávání a přístupu ke zdrojům, indexování záznamů ze schůzí.
Kromě toho se používá jako technika předzpracování pro jiné úlohy zpracování řeči, například k umožnění adaptace na mluvčího pro systémy automatického rozpoznávání řeči (ASR), známé také jako systémy převodu řeči na text. Navzdory velkému pokroku s rozsáhlými předtrénovanými modely, jako je populární ChatGPT na zpracování textu, je zpracování audiozáznamů pro metody strojového učení stále mimořádně náročnou úlohou.
Nejnovější vývoj systémů koncové neuronové diarizace (EEND) podnítil výzkum v této oblasti a posunul paradigma, jak zpracovávat lidskou řeč. Stejně jako většina systémů založených na neuronových sítích jsou však i systémy EEND náročné na data a obtížně se trénují. Záměrem tohoto projektu je posunout tuto oblast kupředu nalezením metod optimalizace tréninkových strategií, a to spojením výhod osvědčených generativních modelů s výkonnými end-to-end přístupy a využitím synergií souvisejících úloh zpracování řeči ke zvýšení výkonnosti SD.
Tento výzkum úzce souvisí s několika běžícími projekty výzkumné skupiny Speech@FIT na Fakultě informačních technologií na Vysokém učení technickém v Brně: NTT corporation, ROZKAZ, od Ministerstva vnitra ČR, a Eloquence, financovaný z programu Horizont Evropa.
Zjišťování ekonomických názorů a příčinných souvislostí z textových dat
Výzva: 30. Veřejná grantová soutěž; OPEN-30-3
Hlavní řešitelka: Jennifer Za Nzambi
Instituce: České vysoké učení technické v Praze
Oblast: informatika
Sociální sítě jsou cosi jako dosud nevyužitá zlatonosná žíla, která skrývá rezervoár názorů, postojů a nálad veřejnosti, a pokud by byly využity, mohly by způsobit převrat ve způsobu, jakým se shromažďují a interpretují názory veřejnosti.
V tomto projektu je představena nová metoda získávání názorů na ekonomické ukazatele a faktory ovlivňující společnost z příspěvků na sociálních sítích pomocí vyladění rozsáhlých jazykových modelů na souborech dat obsahujících příspěvky na sociálních sítích, komentáře a další. Díky vyladění mohou jazykové modely získat schopnost porozumět ekonomickému vyjadřování v příspěvcích zveřejněných na sociálních sítích a napodobit je. Hodnota tohoto projektu je trojí. Předně spojuje pečlivě sestavené datové soubory, díky nimž se model může efektivně učit doménovým specifikům a ekonomickému porozumění na pokročilé úrovni. Dále vytváří metriky založené na porovnávání perplexity protichůdných výroků, které ověřují porozumění ekonomických textů modelem, čímž měří soulad modelu s datovými sadami, na nichž byl vyladěn, a nakonec aplikuje zmíněné modely na datové sady, přičemž získává výsledky naznačující, že přístup založený na modelu může soupeřit a v některých případech překonat předpovědi založené na průzkumech a odborné prognózy trendů ekonomických ukazatelů.
Nad rámec této studie by předložené metody a zjištění mohly připravit půdu pro další aplikace vylaďování jazykových modelů jako doplňku nebo potenciální alternativy k tradičním metodám založeným na průzkumech.
Tento výzkum je financován Evropskou radou pro výzkum (ERC) v rámci programu Evropské unie pro výzkum a inovace Horizont 2020 (grantová dohoda č. 101002898).
Slama – Slovanský velký jazykový model pro umělou inteligenci
Výzva: 29. Veřejná grantová soutěž; OPEN-29-48
Hlavní řešitel: Aleš Horák
Instituce: Masarykova univerzita
Oblast: informatika

Projekt Slama (Slavonic Large Foundational Language Model for AI) se zaměřuje na vytvoření nového základního jazykového modelu, který se soustředí na hlavní slovanské jazyky píšící latinkou (čeština, slovenština, polština, ...). Hlavním cílem projektu je prozkoumat výkonnostní rozdíly mezi nejmodernějšími předtrénovanými vícejazyčnými modely (kde většinu trénovacích dat představují anglické texty) a modelem přizpůsobeným speciálně pro slovanskou jazykovou skupinu. Výzkum se zaměří na vývoj generativních modelů, jejichž trénovací data jsou vyváženější ve prospěch slovanské jazykové skupiny než angličtiny. Proto by měly poskytovat lepší výsledky při použití v nástrojích umělé inteligence zpracovávajících především slovanské jazyky. Výsledný fundamentální model pak bude možné snadno použít v řadě úloh umělé inteligence.
3D rekonstrukce pro manipulaci s objekty
Výzva: 29. Veřejná grantová soutěž; OPEN-29-7
Hlavní řešitel: Varun Burde
Instituce: České vysoké učení technické v Praze
Oblast: Informatika
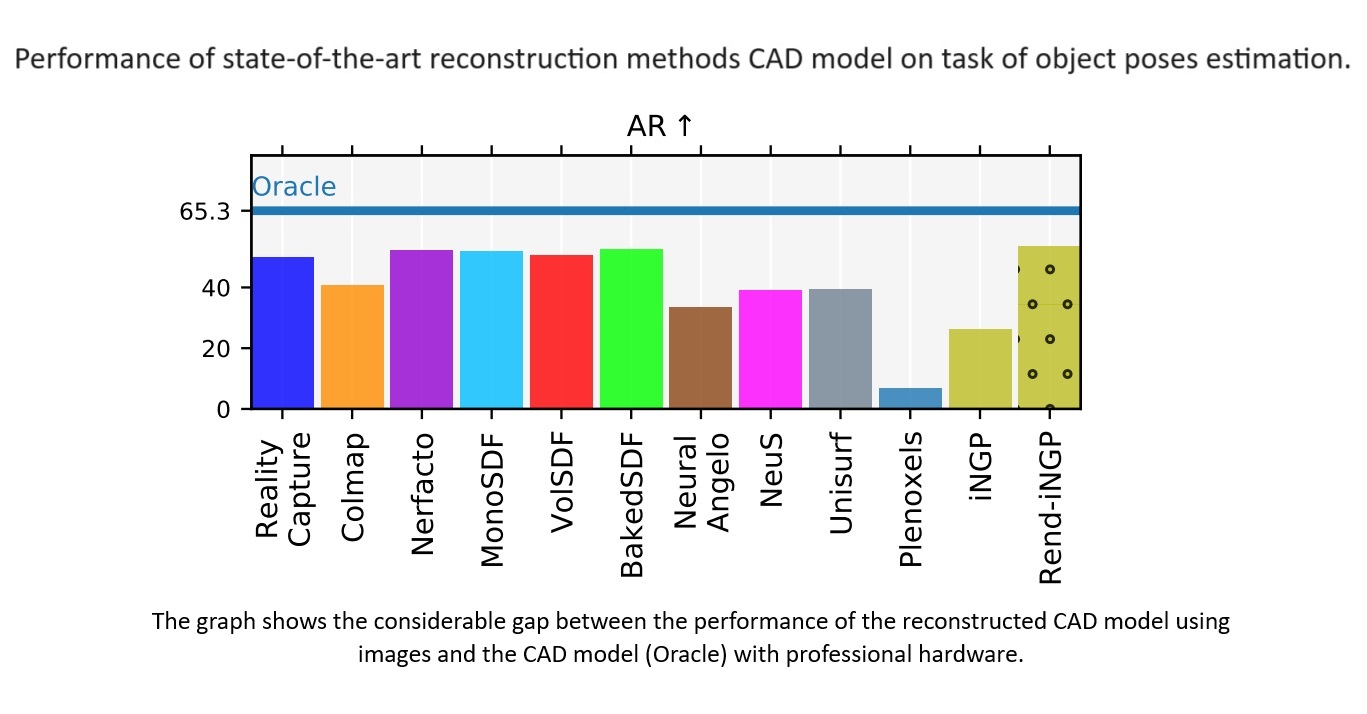
Manipulace s objekty je základní schopností mnoha robotů. Předpokladem manipulace je odhad pózy objektu, kdy je cílem odhadnout polohu a orientaci objektu vzhledem k robotovi, protože tyto informace informují robota o tom, jak s objektem komunikovat (jak se k němu přiblížit, jak ho uchopit atd.). Současný nejmodernější algoritmus odhadu pózy objektu se opírá o určitou reprezentaci pro odhad pózy objektu. Získání vysoce přesných CAD modelů může být náročné a zdlouhavé a navíc může vyžadovat profesionální hardware, například laserový skener. Náš předchozí výsledek ukázal, že nejmodernější metody dokáží dobře rekonstruovat jednoduché objekty, ale aby bylo možné pojmout širší škálu objektů, je potřeba současnou generaci algoritmů výrazně vylepšit v několika osách, jako je doba běhu, odolnost vůči změnám prostředí a přesnost rekonstrukce/reprezentace. Cílem našeho výzkumu je zrychlit techniky 3D rekonstrukce a využít moderní implicitní reprezentaci objektů, což umožní nasazení v reálném čase v robotice a přizpůsobení složitějším objektům. Výpočetní infrastruktura IT4Innovations poskytuje platformu pro práci a trénink s rozsáhlými soubory dat. Výzkum je součástí Studentské grantové soutěže ČVUT č.: SGS23/172/OHK3/3T/13.
High Performance Language Technologies (HPLT)
Výzva: 28. Veřejná grantová soutěž; OPEN-28-66
Hlavní řešitel: David Antoš
Instituce: CESNET
Oblast: Informatika
Velké jazykové modely (LLM) stojí za nedávným pokrokem v oblasti umělé inteligence, zejména v oblasti užití přirozeného jazyka při komunikaci s počítači. Předtrénované LLM jsou pravidelně používány v chatbotech, vyhledávačích, vydávají doporučení, klasifikují řeč a dokumenty a umožňují mnoho podobných aplikací. Trénování LLM je v rukou několika velkých společností, které většinou nevěnují velkou pozornost reprodukovatelnosti, minimalizaci zkreslení a energetické účinnost, stejně jako rovnou pozornost všem jazykům.
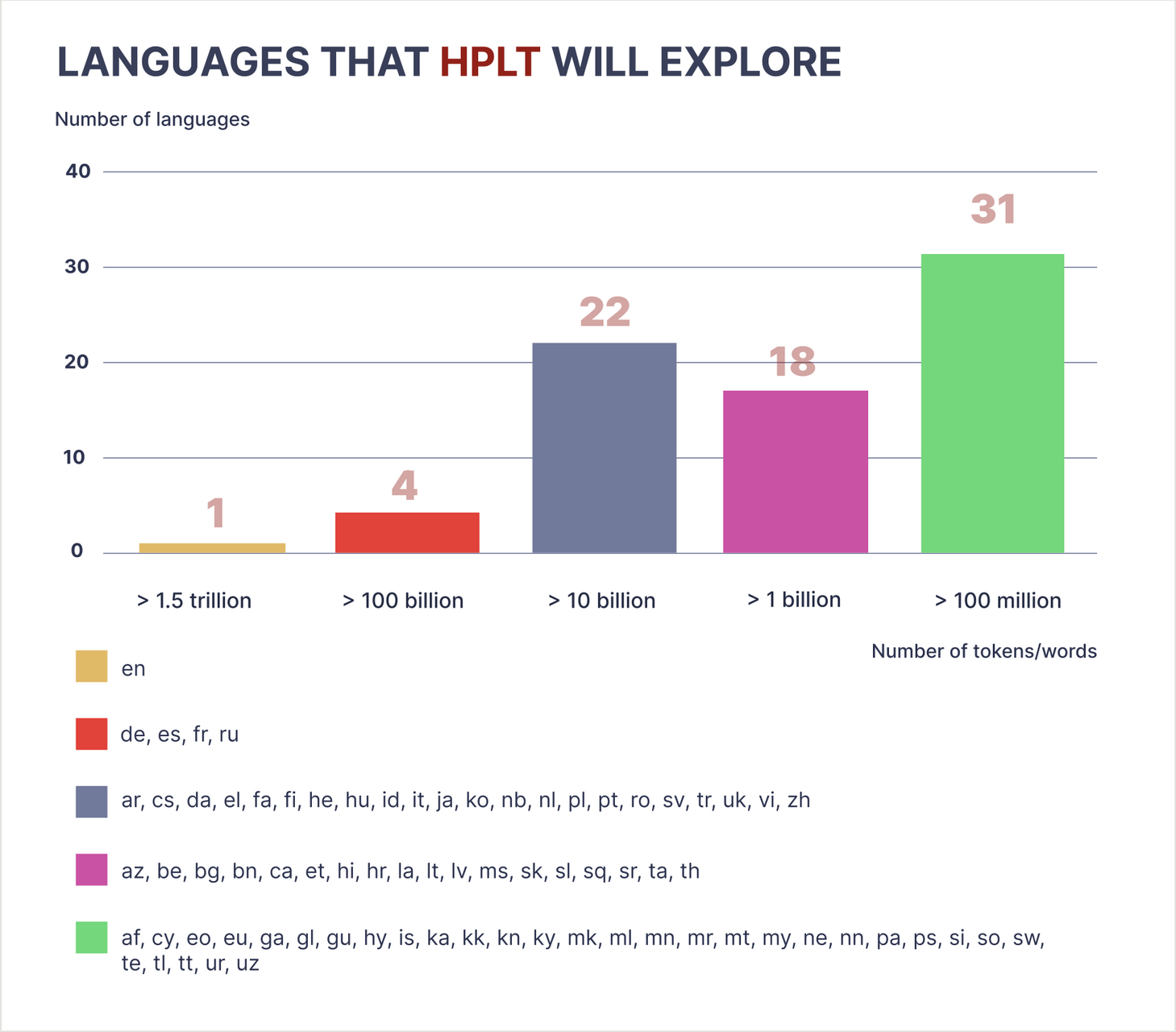
Cílem projektu HPLT, který koordinuje Univerzita Karlova v Praze a podpořen je programem Horizont Evropa, je trénování otevřených jazykových modelů pro více než 50 jazyků. Projekt bude využívat přes 7 PB archivovaných webových stránek, paralelních korpusů a dalších zdrojů. S využitím výpočetní síly IT4Innovations bude vybudována největší kolekce otevřených, reprodukovatelných jazykových a překladatelských modelů. Projekt bude dokumentovat, jak byla data extrahována a jak byly modely budovány, a zajistí tak nejvyšší standardy otevřené vědy, reprodukovatelnosti a transparentnosti.
Vícedokumentová sumarizace odborné literatury
Výzva: 28. Veřejná grantová soutěž; OPEN-28-72
Hlavní řešitel: Martin Dočekal
Instituce: Vysoké učení technické v Brně
Oblast: Informatika

Nikdy v dějinách nebylo publikováno tolik vědeckých prací jako v dnešní době. Tento fakt způsobuje, že i pro odborníky je náročné zůstat v obraze a je velmi jednoduché přehlédnout relevantní informace. Dnes běžně vznikají články shrnující aktuální stav poznání na dané téma, či autoři ve svém článku vyčlení speciální sekci shrnující příbuzné práce. Díky těmto textům je pak snadnější vnímat informace v širším kontextu.
Vypracování takovýchto textů vyžaduje nemalé lidské úsilí, ale díky pokroku ve strojovém učení je možné vyvinout modely, které pomohou s jejich tvorbu, či umožní uživateli si vytvořit shrnutí na vyžádání. Cílem projektu Martina Dočekala je využít infrastrukturu IT4Innovations k natrénování neuronové sítě schopné generovat shrnutí dané skupiny vědeckých článků.
Deterministický simulátor dopravního toku – II. fáze
Výzva: 24. Veřejná grantová soutěž; OPEN-24-65
Hlavní řešitel: Martin Šurkovský
Instituce: VŠB-TUO, IT4Innovations
Oblast: Informatika
Deterministický simulátor dopravního toku se používá pro testování algoritmů řešících optimalizaci dopravního toku ve městě. Pro představu, běžná navigace naviguje auto po městě tak, že preferuje nejkratší vzdálenost nebo nejkratší čas dojezdu. To může vést k vytváření zácp ve městě. S vyžitím dopravního simulátoru se snažíme optimalizovat celkový dopravní tok tak, aby k zácpám ideálně nedocházelo vůbec. Determinističnost simulátoru zajistí to, že pro stejné vstupní nastavení je výsledek simulace vždy totožný. Tato vlastnost bývá zřídka kdy splněna v prostředí superpočítače a je důležitá z pohledu porovnávání výsledků a jejich opakovatelnosti. Na projektu se podílí firma Sygic a je zároveň řešen v rámci evropského projektu HORIZON 2020 – EVEREST, který se zabývá usnadněním optimálního využívání heterogenních výpočetních zdrojů, tj. jak klasických procesorů, tak specializovaných akcelerátorů.
THEaiTRE GPT2 Recycling
Výzva: mimořádná výzva 24. Veřejné grantové soutěže, OPEN-24-11
Hlavní řešitel: Rudolf Rosa
Instituce: Univerzita Karlova
Oblast: Informatika
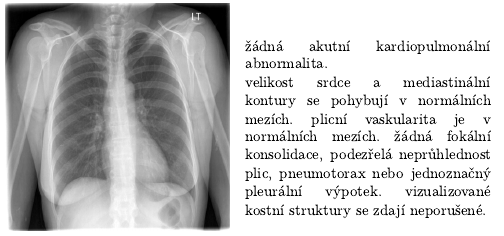
Ostravské superpočítače jsme využili v rámci našeho výzkumu a vývoje na Ústavu formální a aplikované lingvistiky na Matematicko-fyzikální fakultě Univerzity Karlovy. Díky výkonným GPU s vysokou kapacitou paměti jsme mohli natrénovat českou verzi velkého neuronového generativního jazykového modelu GPT-2. Generativní jazykový model je nástroj, který například umí pro zadaný začátek textu navrhnout jeho možné pokračování; tj. například pro text "Ráno jsem vstal a šel do [...]" může navrhnout například "práce" nebo "koupelny". Model GPT-2 byl dosud dostupný pouze v angličtině, jeho českou verzi využíváme například pro automatické generování popisů rentgenových snímků či pro generování scénářů divadelních her v projektu THEaiTRE.
Odhadování pozic objektů z obrázků
Výzva: mimořádná výzva 24. Veřejné grantové soutěže, OPEN-24-10
Hlavní řešitel: Vladimir Petrík
Instituce: České vysoké učení technické v Praze
Oblast: Informatika

Naším cílem je vytvořit algoritmus pro automatické učení dovedností pro robotickou manipulaci (např. sestavení nábytku) na základě videí stažených např. z YouTube. U stažených videí ale neznáme typ kamery a její kalibraci, takže je obtížné odhadnout pozice objektů v zaznamenané scéně. Řešení nabízí FocalPose, naše metoda založená na render-and-compare strategii, která byla navržena pro odhadování pozice mezi kamerou a objektem společně s ohniskovou vzdáleností kamery. Vstupem do FocalPose je RGB obrázek, který zobrazuje známý objekt. Metoda FocalPose je trénována na milionech synteticky generovaných snímcích pomocí několika výpočetních uzlů na superpočítači Karolina, což vede k robustnímu algoritmu, který funguje i na fotkách komplexních scén. Práce byla publikována na CVPR 2022, jedné z hlavních konferencí o počítačovém vidění, kde bylo letos přijato 2064 ze 8161 zaslaných příspěvků.
Transfer Learning pro extrakci klíčových frází
Výzva: 21. Veřejná grantová soutěž
Hlavní řešitel: Ing. Martin Dočekal
Instituce: Fakulta informačních technologií VUT v Brně
Oblast: Informatika
Čím dál tím více se ukazuje, že v dnešní záplavě dat je těžké najít relevantní dokument obsahující informace, které hledáme. Došli jsme do stavu, že je pro člověka těžko uchopitelné vyhledávání informací bez použití automatického nástroje, jakým je například vyhledávač. Dokonce však i za použití vyhledávače dostáváme velké množství dokumentů o jejichž relevanci už musí rozhodnout sám uživatel. S tímto problémem mohou pomoci klíčové fráze, které přibližují obsah dokumentu v kompaktní formě. Běžná klíčová fráze má několik málo slov. Pokud se jedná pouze o jedno slovo nazýváme ji známějším pojmem, a to sice klíčovým slovem.
V našem projektu se zaměřujeme na získávání klíčových frází z rozsáhlých (průměrně přes 83 000 slov) dokumentů v českém jazyce jako jsou knihy. Použité dokumenty jsou navíc zatíženy chybami, jelikož byly vytvořeny automatickou digitalizací. Extrahované klíčové fráze z tohoto druhu dokumentů by mohly být mimo jiné použity knihovnicemi a knihovníky při jejich práci.
Pro hledání klíčových frází používáme rozsáhlé neuronové sítě, které jsou schopny vytvořit kontextově závislé reprezentace slov. Na základě těchto reprezentací následně síť rozhodne, zdali danou sekvenci slov lze považovat za klíčovou frázi.
VYSOCE VÍCEJAZYČNÝ NEURÁLNÍ STROJOVÝ PŘEKLAD VYUŽÍVAJÍCÍ UČENÍ BEZ UČITELE
Výzva: 20. Veřejná grantová soutěž
Hlavní řešitel: Ing. Josef Jon
Instituce: Vysoké učení technické v Brně
Oblast: Informatika
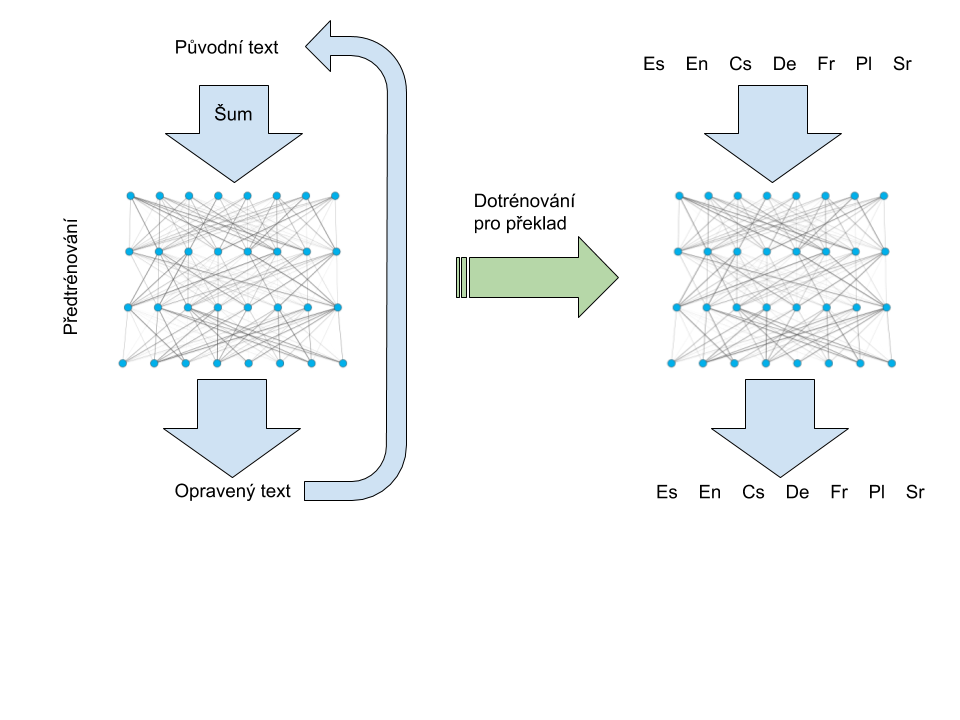
Strojový překlad lidského jazyka učinil velký pokrok v souvislosti s vývojem strojového učení. Texty přeložené neurálním strojovým překladem (NMT) jsou za určitých podmínek dokonce srovnatelné s překladem lidským. Podmínkou je, že pro daný jazykový pár je k dispozici velké množství paralelních, člověkem přeložených textů pro trénování modelu. Těch je však velmi málo. Zlepšení kvality NMT v ostatních jazycích je založeno na předtrénovaných modelech neuronových sítí pro reprezentaci jazyka. Ty umožňují využít velkých objemů textů nalezených na internetu, do nichž je však uměle přidán šum, kdy některá slova jsou vypuštěna, nebo nahrazena. Úkolem je zrekonstruovat původní text. Trénováním na této úloze se model vlastně mimochodem učí reprezentovat jazyk a porozumět mu, protože tyto schopnosti jsou nutné k tomu, aby text dokázal správně opravit. Předtrénované modely lze doladit ke koncovým úkolům pomocí výrazně menšího množství dat, než kdyby se trénovaly od začátku. Ukazuje se, že čím více je způsob přidávání šumu v předtrénovací fázi podobný koncovému úkolu, tím lepší je výsledek. Cílem inženýra Jona, který pro svůj projekt získal téměř 1,2 milionu jádrohodin, je prozkoumat varianty šumových funkcí, jež jsou podobné překladu (např. nahrazení slova nebo fráze jeho překladem), a výsledné modely použít pro překlad v jazykových párech s malým množstvím trénovacích dat.
DRVOSTEP
Výzva: 16. Veřejná grantová soutěž
Hlavní řešitel: Martin Kolář, M.Sc.
Instituce: Vysoké učení technické v Brně
Oblast: Informatika

Více než 1,5 milionu jádrohodin získal Martin Kolář z Vysokého učení technického v Brně na výzkum kvality překladu pro velký počet jazyků. Současný výzkum se obecně zaměřuje na vývoj metod, které se učí překládat text mezi dvěma jazyky, přičemž na překlad mezi více než 6 jazyky se prozatím nikdo nezaměřil. Cílem projektu Martina Koláře je zlepšit kvalitu překladu, kvantifikovat složitost jazyků a tím odpovědět na otázku, jaký je rozdíl mezi kvalitou přímého překladu oproti překladu s využitím společného jazyka. S pomocí našeho superpočítače chce výzkumný tým z VUT v Brně analyzovat stovky jazyků a vytvořit volně dostupný online překladač.
VÝVOJ KNIHOVEN A NÁSTROJŮ LABORATOŘE PRO VÝZKUM INFRASTRUKTURY
Výzva: 15. Veřejná grantová soutěž
Hlavní řešitel: Petr Strakoš a Lubomír Říha
Instituce: IT4Innovations
Oblast: Informatika
Kolegové z Laboratoře pro výzkum infrastruktury IT4Innovations získali téměř 1,5 milionu jádrohodin pro vývoj nástrojů, které používají uživatelé našich superpočítačů pro výzkum. Klíčovými tématy projektu jsou energetická efektivita v HPC, vývoj numerické knihovny ESPRESO a vizualizačních nástrojů. Přidělené výpočetní zdroje využije výzkumná skupina k analýze chování nových aplikací a jejich dynamickému ladění s cílem snížit spotřebu energie při jejich spouštění na superpočítači. U knihovny ESPRESO, vlajkové lodi našeho výzkumu, bude řešeno například vylepšení výkonu při spuštění na jednom výpočetním uzlu a nasazení na systémech s grafickými akcelerátory. Co se vizualizačních nástrojů týká, chtějí kolegové vytvořit open source nástroj pro vizualizace vědeckých dat, který bude dostupný uživatelům naší infrastruktury. Vizualizační nástroj bude založený na populární 3D sadě softwaru Blender, konkrétně na jeho verzi 2.80, která má být vydána v 1. čtvrtletí letošního roku.
ANALÝZA PŘÍČIN A PROGNÓZY UDÁLOSTÍ PCRF V SÍTÍCH 4G A 5G
Výzva: 15. Veřejná grantová soutěž
Hlavní řešitel: Miroslav Vozňák
Instituce: IT4Innovations a Fakulta elektrotechniky a informatiky VŠB-TUO
Oblast: Informatika

Miroslav Vozňák a jeho výzkumný tým z Fakulty elektrotechniky a informatiky VŠB – Technické univerzity Ostrava získal téměř půl milionu jádrohodin pro projekt, jehož cílem je zvýšit spolehlivost a snížit náklady na udržování nových technologií zajišťujících provoz 4G a 5G mobilních sítí. Tento výzkum probíhá na základě spolupráce s centrem kompetence pro vývoj sítí provozovaným T-Mobile Czech Republic a.s. Společně chtějí nalézt klíčové zdroje dat, shromáždit informace o technických problémech a identifikovat ukazatele výkonu právě pro zvýšení spolehlivosti sítě a zabránění problémům v síti. Výsledky zpracování dat pomocí superpočítače budou sloužit pro plánované využití strojového učení například pro odhalení a klasifikaci anomálií v mobilních sítích.
SROVNÁNÍ METOD VNOŘENÍ SLOV
Výzva: 12. Veřejná grantová soutěž
Hlavní řešitel: Ing. Martin Fajčík
Instituce: Vysoké učení technické v Brně
Oblast: Informatika
.png)
Způsob číselné reprezentace slov používaný v počítačovém zpracování přirozeného jazyka se označuje jako technika vnoření slov. Spočívá ve vytvoření vektoru pro každé slovo. Pokročilé metody vnoření slov nacházejí uplatnění v různých oblastech souvisejících například s rozpoznáváním řeči a překladem. Cílem projektu Ing. Martina Fajčíka z Vysokého učení technického v Brně, který získal 850 000 jádrohodin, je experimentovat se současnými nejmodernějšími technikami vnoření slov (statistickými i prediktivními) jejich učením pomocí rozsáhlých datových souborů. Tým vědců chce identifikovat slabá místa různých technik a navrhnout způsoby pro jejich další zlepšení. Práce na projektu zahrnuje také pochopení vztahů vektorů slov s jejich skutečným významem. Zajímavostí bude i zpracování homonym, synonym, antonym a hyponym. Z modelů je možné odhadnout nejen vztahy mezi slovy, které se „naučily“, ale dokonce vyjádřit i míru těchto vztahů a pracovat se slovní aritmetikou (například jak jsou si slova podobná). Uveďme si příklad: Když od vektoru slova král odečteme vektor slova muž a přidáme vektor slova žena – dostaneme vektor blízký jakému slovu?
ESPRESO FEM – MODUL PŘENOSU TEPLA
Výzva: 10. Veřejná grantová soutěž
Hlavní řešitel: Ing. Tomáš Brzobohatý, Ph.D.
Instituce: IT4Innovations
Oblast: Informatika

Projekt Dr. Tomáše Brzobohatého „ESPRESO FEM – Heat Transfer Module“ získal 2 425 000 jádrohodin. Výzkumný tým se bude zabývat vývojem a testováním komplexní a masivně paralelní knihovny založené na metodě konečných prvků, pro simulaci problémů přenosu tepla a jejich optimalizaci. Součástí knihovny je masivně paralelní iterační řešič ESPRESO vyvíjený na IT4Innovations.
VÝVOJ KNIHOVNY BEM4I
Výzva: 9. Veřejná grantová soutěž
Hlavní řešitel: Michal Merta
Instituce: IT4Innovations
Oblast: Informatika

Vědci z IT4Innovations pokračují ve vývoji knihovny paralelních řešičů založených na metodě hraničních prvků (BEM). V rámci předchozího projektu byla tato knihovna (BEM4I) akcelerována pomocí koprocesorů Intel Xeon Phi (Knights Corner, KNC), což doplnilo již existující a funkční paralelizaci pomocí OpenMP a MPI. V této fázi se se zaměří na další optimalizace kódu a jeho testování na nové generaci procesorů Intel Xeon Phi (Knights Landing, KNL). Cílem projektu je vyvinout efektivní knihovnu pro rychlé řešení hraničních integrálních rovnic. Vědci se budou zabývat vektorizací sestavení systémových matic a paralelizací v distribuované paměti. BEM4I bude možné využít při řešení reálných inženýrských problémů z oblasti šíření zvuku či úloh tvarové optimalizace.