Most supercomputing centres have set themselves the goal of lowering entry barriers to the world of high-performance computing for all users from research institutions, industry, state administration, hospitals, and other institutions without sacrificing execution performance. To this end, IT4Innovations' research activity in the areas of distributed systems, scheduling, remote execution, and security has been intensified.
The flagship research team is focused on the development of the HPC-as-a-Service concept (HaaS), which is a complex solution for HPC centres to make their HPC services available to a much broader user base. HPC-as-a-Service allows users to access HPC infrastructure without having to buy and manage their own physical servers or data centre infrastructure. Moreover, this approach lowers the entry barrier for everybody who is interested in using massively parallel computers, but often lacking the necessary level of expertise in this area. IT4Innovations has long been developing these HPC platforms and related software packages (HyperLoom, HEAppE, etc.), which are not dependent on just one type of infrastructure and as such they can be run by other supercomputing centres allowing them that can offer these packages to their users. Through the development of ́platforms, the user base is broadened to include academia, SMEs, and industrial companies that can take advantage of the HPC technology without an upfront investment in the hardware.
Simultaneously, a large portion of HPC workloads are scientific pipelines composed by domain specialists who do not have deeper knowledge and experience of and with HPC technologies, respectively. Therefore, the objective of the flagship research team is also to continue in the development of programming models allowing users to easily define dependencies between various computational tasks as well as runtime layers capable of their efficient execution in large scale distributed environments (e.g., HyperLoom software). Last but not least, the objective is also to make results available thus maximizing their potential impact.
Investigators:
• Dr Jan Martinovič
• Dr Stanislav Böhm
• Dr Václav Svatoň

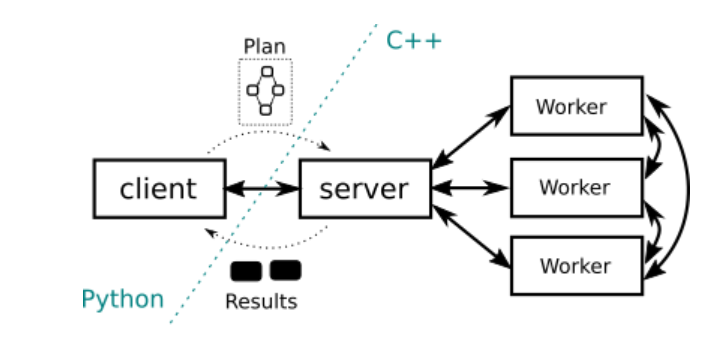
HYPERLOOM
HyperLoom is a set of tools for defining and executing workflow pipelines in large-scale distributed environments. Not only it provides Python API to describe workload and its dependencies in abstract way but also it allows efficient runtime to execute pipelines containing millions of tasks on hundreds to thousands of nodes.
The HyperLoom tools have been developed independently of the used infrastructure. They can be operated on both an HPC cluster and cloud infrastructure.
For more information SEE.
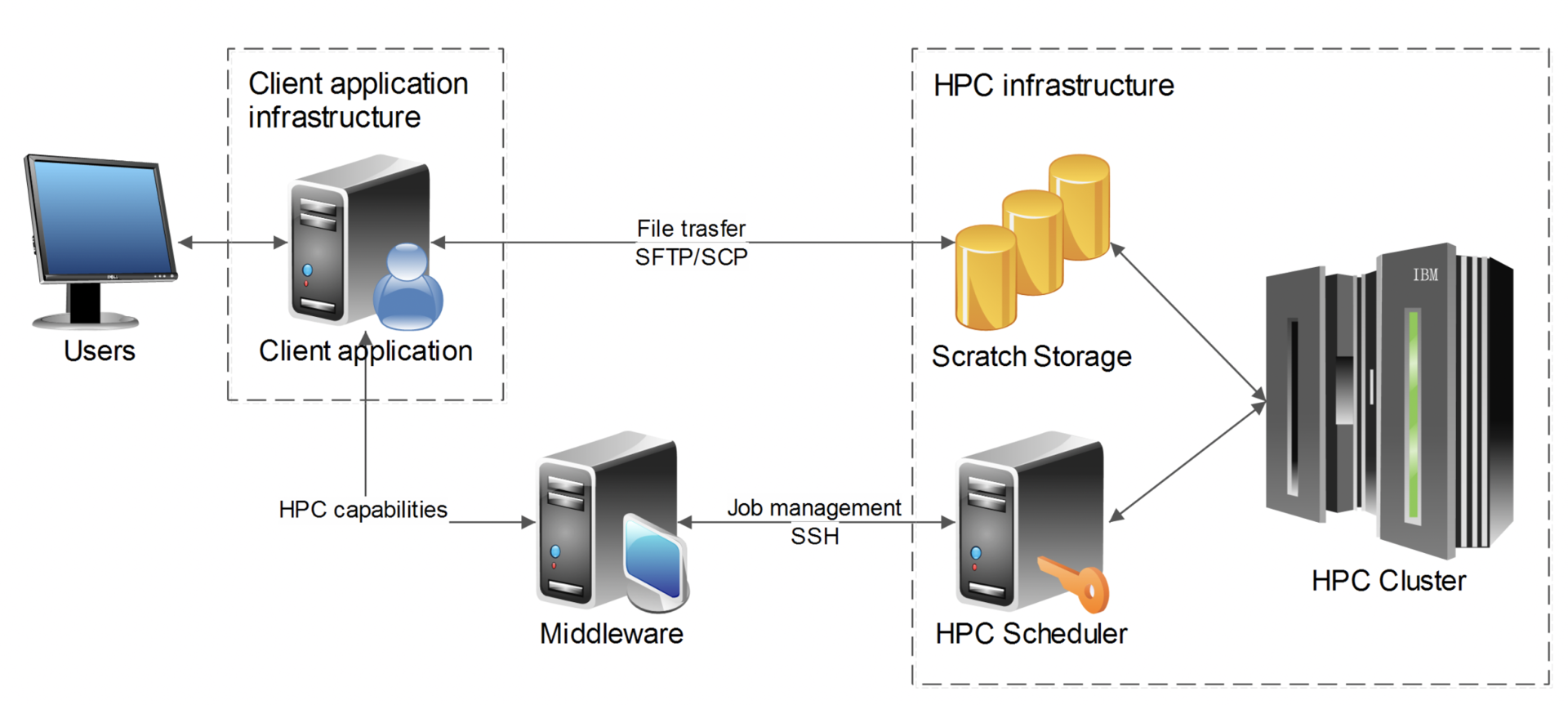
HEAPPE (HIGH-END APPLICATION EXECUTION MIDDLEWARE)
To provide simple and intuitive access to a supercomputing infrastructure, an application framework called HEAppE has been developed. This framework utilizes a mid-layer principle, which is known as middleware in software terminology. Middleware manages and provides information about submitted and running jobs and their data transferred between a client application and an HPC infrastructure. HEAppE has been developed within a joint project of IT4Innovations National Supercomputing Center and the transnational DHI company, which is one of the leaders in the field of hydrological software development.
Primarily developed for application at IT4Innovations in the field of hydrological modelling, HEAppE has already been both used in many different fields and operated by several supercomputing centres. The HEAppE platform is intended not only for one particular type of hardware for the existing high-performance and future exascale computing systems but also for the use of different systems in different supercomputing centres. By means of HEAppE, all interested parties may benefit from HPC technologies. HEAppE allows execution of required computations and simulations on HPC infrastructure, monitor the progress, and notify the user should the need arise. It provides necessary functions for job management, monitoring and reporting, user authentication and authorization, file transfer, encryption, and various notification mechanisms.
For more information SEE.


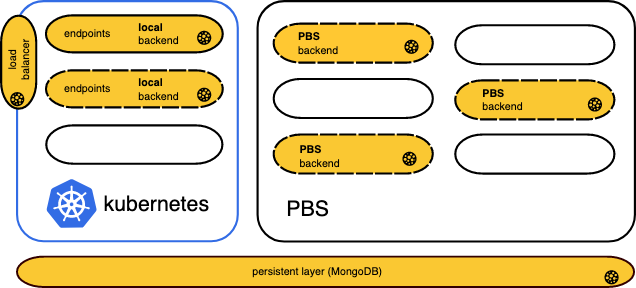
AI – MLOC & HEAPPE
MLoC stands for an open-sourcee Machine Learning as a Service solution” developed in order to lower the entry barrier to large-scale machine learning. It allows users to define artificial neural network architectures and manage their states through the REST API. MLoC features multiple supporting layers where Neural Network lifecycle numerical operations may be executed depending on their computational complexity.
Computationally demanding tasks, with low latency constraints, such as a neural network training may be offloaded to IT4Innovations HPC infrastructure. In contrast, lightweight tasks, such as model inference, expecting a quick response rate may be executed directly on the API infrastructure. MLoC closely operates with Heappe - IT4Innovations internal application framework.
For more information SEE.
use cases
A very important part of this flagship activity is to ensure the impact on the end user. The above-mentioned technologies have already been used before and are currently used in a number of projects.
NATIONAL PROJECTS
- Floreon+ – The evaluation of information to support decision-making within crisis management processes, namely floods. The development of a system to monitor, model, predict and support solutions to crisis situations, with a special focus on the Moravian - Silesian Region.
www.floreon.eu
- MOLDIMED – The main objective of the platform is to provide researchers focused on clinical massively parallel sequencing data with easy and intuitive access to the HPC infrastructure via a specialised web interface.

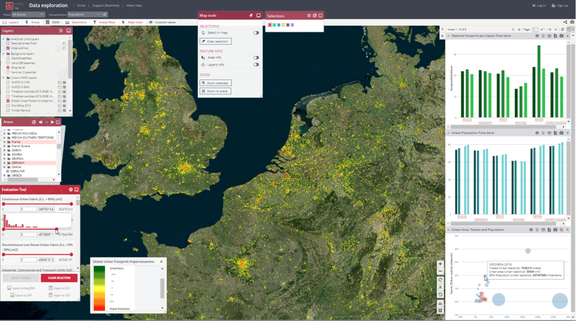
INTERNATIONAL PROJECTS
- ESA – the European Space Agency launched an initiative entitled Thematic Exploitation Platform (TEP), the objective of which was to develop and implement a set of thematically oriented platforms, virtual environments facilitating Earth observation generated data search.
- ExCAPE – Within the project, IT4I was involved in development of state-of-the-art scalable algorithms and implementations suitable for running on future exascale machines.
- LEXIS – The objective of the project is to build an advanced engineering platform leveraging modern technologies from High Performance Computing, Big Data, and Cloud Computing.
www.lexis-project.eu - ExaQUte – The aim of the three-year long project ExaQUte is to develop new methods for solving complex engineering problems using numerical simulations on future exascale systems.
www.exaqute.eu